






















This article is republished from the website : pcfe's blog
Source:
https://blog.pcfe.net/hugo/
Original title:
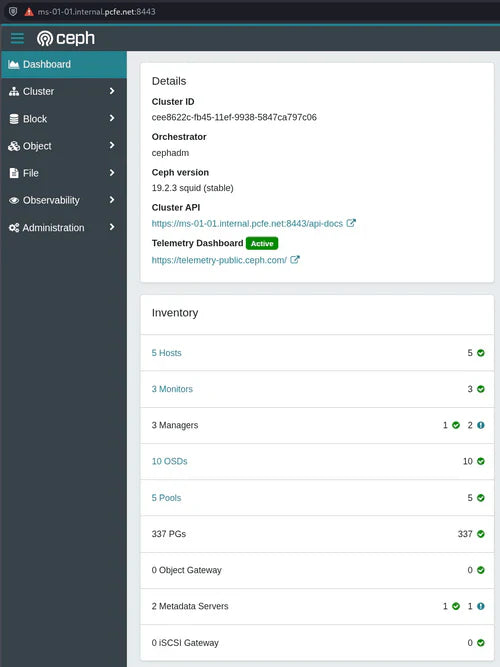
Minisforum MS-01, CentOS Stream 9, Ceph Squid install
Author:
pcfe
This republication has been authorized by the original author. For further republication, please contact the original author.
The views and opinions expressed in this article are those of the author and do not necessarily reflect the official position of Minisforum.